Machine Learning Advent Calendar 2014の12日目。
最近半教師あり学習に興味があってちょっと勉強してみたのでそれについて書いてみる。自分が勉強した時に読んだ文献も下の方に書いたのでもし興味があれば。
半教師あり学習はラベル付きデータに加えてラベル無しデータも使って学習できるということですごく魅力的なんだけど、何も考えずに使うと教師あり学習より精度が落ちることがよくある。
ラベル無しデータはその名の通りどのクラスに属すかが分かっていないデータなので、何かしらの モデル に基いてそのデータがどのクラスに属するかを仮定してやらないといけない。つまりデータの分布(モデル)に仮定を置かないといけない。半教師あり学習をする上ではこれが 一番重要。
Introduction to Semi-Supervised Learningのp.15にもこう書いてある。
the model assumption plays an important role in semi-supervised learning.
というわけでここではいろいろな半教師あり学習手法についてその手法が仮定しているモデルについてまとめる。
Self-training
概要
ある分類器fを使ってラベル付きデータのみで学習し、ラベルなしデータの分類をする。その後分類したラベルなしデータのうち高い 確信度 で分類できたもののいくつかをラベルありデータとみなして再度学習する。これの繰り返し。Self-trainingはwrapper methodなのでどんな分類器でも使える。
Unsupervised word sense disambiguation rivaling supervised methods, ACL 1995
モデル仮定
自分が(高い確信度で)分類したデータの分類結果は正しいこと。これは異なるクラスに属すデータがwell-separatedであることを意味する。
Mixture Models (semi-supervised GMM)
概要
EMで推定する時のデータの寄与率(どのクラスに属すか)を、ラベル付きデータについてはそのデータが属すクラスでのみ値1を取るように固定し、ラベル無しデータについては通常のGMMの時と同様に計算する。GMMを例に出したけど混合多項分布を使ったテキスト分類の論文が有名っぽい。
Text Classification from Labeled and Unlabeled Documents using EM, Machine Learning 2000
モデル仮定
トートロジーのように聞こえるかもしれないけど、 仮定したモデルが正しいこと。 例えば実際のデータは混合正規分布に従ってないのにsemi-supervised GMMで解こうとしてもうまくいかない。
Co-training
概要
データが二つの素性に分解できるとする(例えばwebページの分類をするときは画像と文章とか)。それぞれの素性について分類器を個別に用意し、ラベル付きデータのみでそれぞれ学習する。分類器1で高い確信度で分類できたラベルなしデータを分類器2での次回の学習に用い、逆に分類器2で高い確信度で分類できたラベルなしデータを分類器1での次回の学習に用いる。これを繰り返す。Self-trainingに似てるけど分類器を二つ使うところがポイント。これもWrapper method。
Combining labeled and unlabeled data with co-training, COLT 1998
モデル仮定
- 個々の分類器だけでも 良い 分類が出来ること
- 分解された二つの素性はラベルが与えられた上で 条件付き独立 であること
2が成り立たないと、どちらの分類器も同じような結果を出すから意味が無い。
Graph-based SSL (Label propagation)
概要
Label propagationはGraph-based SSLの一つ。ラベルありラベルなしに関係なく、データ間の類似度に基いてグラフを構築する。ノードはデータで(重み付き)エッジはデータ間の類似度。類似度の計算にはガウシアンカーネルを用いることが多い。構築したグラフ上でラベルありデータからラベルなしデータへ ラベルを伝搬 させ、ラベルなしデータのラベルを推定する。ラベルなしデータの近くにラベル1のラベルありデータが多く有れば、ラベル1に分類されるイメージ。ちなみにこれは元々グラフで表されるようなデータ(ソーシャルネットワークとか)に対してもよく用いられる。
Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions, ICML 2003
モデル仮定
(大きい重みで) 接続している2ノードは同じラベルを持つこと。 ラベルが違うデータでも類似度が大きくなることがよくあるような場合はうまくいかない。
S3VM
概要
Semi-supervised support vector machineのこと。通常のSVMはラベルありデータのみを見て決定境界を決めるが、S3VMではラベルなしデータも考慮して、出来るだけ決定境界がラベルなしデータの上を通らないようにする。実際に例を見てみるとわかりやすいかな。ちなみに通常のSVMと違ってコスト関数が凸にならないから扱いづらい。
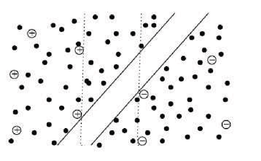{kind=link}
Statistical Learning Theory (本)
モデル仮定
異なるクラスに属すデータがwell-separatedであること。言い換えると、特徴空間において決定境界付近には(ラベルなし)データが少ないこと。
良い文献
多分自分はこの順で読んだはず。もともとある程度半教師あり学習についての知識はあったけど。
半教師あり学習とは結局のところ何なのか? - Seeking for my unique color. 半教師あり学習 - SlideShare
半教師あり学習に関する簡単な俯瞰。良い。多分下の方に挙げる本を読めばこの記事に書いてあることは全て書いてあるんだけど、まずは日本語で俯瞰したい人におすすめ。
satomacoto: Pythonでラベル伝搬法を試してみる
Label spreadingっていうGraph-based SSLについての簡単な説明とその実装が書いてある。実装がすごい簡単でいいね。
Label propagationについて詳細に説明してる記事。簡単な例を使って説明してるのでわかりやすい。最適化問題としての定式化とかについても書いてある。
ビッグデータ時代のサンタ狩り - ML Advent Calendar 2013 最終日
@sleepy_yoshiさんによる去年のML Advent Calendarのおおとり。Semi-supervised GMM(と近年問題になっているサンタ狩り)について書いてある。全てラベルなしの場合、全てラベルありの場合、どっちもある場合(半教師あり)について分けて比較してる。めちゃくちゃ詳細に説明してあるしすごくわかりやすい。超おすすめ。
Node Classification in Social Networks
グラフ上のノード分類という問題からいろいろなGraph-based SSLについて触れてる。それぞれの簡単な違いとかランダムウォークとしての解釈とか最適化問題としての解釈とか書かれてて良い。
")
- 作者: Xiaojin Zhu,Andrew B. Goldberg
- 出版社/メーカー: Morgan and Claypool Publishers
- 発売日: 2009/09/15
- メディア: ペーパーバック
- 購入: 1人 クリック: 52回
- この商品を含むブログ (9件) を見る
SSLの入門書。この記事にまとめたことは全てこの本に書いてある。Label propagationを提案した人が書いた本。参考文献リストとAppendixを除けば100ページもないし読みやすいのですぐ読める。全体を俯瞰したい人には超おすすめ。
")
Semi-Supervised Learning (Adaptive Computation and Machine Learning series)
- 作者: Olivier Chapelle,Bernhard Schoelkopf,Alexander Zien
- 出版社/メーカー: The MIT Press
- 発売日: 2010/01/22
- メディア: ペーパーバック
- 購入: 1人 クリック: 4回
- この商品を含むブログを見る
厚い本だけどこれもSSLの入門書。Introduction to SSLよりもっと詳しく色々書いてある。いろんな文献から引用されてるからこっちのほうが定番なのかな。読んでる途中なので全体としておすすめできるかはわからない。